随机数生成算法是一个很常用的算法,很多场景都会用到。许多语言(Java、Python等)也都支持生成符合某种分布(均匀分布、高斯分布等)的随机数。但是并不是所有的数据都符合某种已知的分布,如果我们想生成符合分布\(f(x)\)的随机数,应该怎么办?这种根据某个概率分布函数\(f(x)\)生成随机数的问题我们会另起一篇文章讨论。这篇文章主要讨论基于离散数据的权重生成随机数的方法。
业务场景
配送仿真系统中骑手的初始位置选择。经验假设:开工时骑手会选择在某些热门商家周围等待(因为有很大的概率接到单)。以商家的单量作为权重,基于权重随机选择商家作为骑手的初始位置,也就是说商家的单量越多,骑手出现在该商家的概率越大。
实现方案
如果有5个元素A、B、C、D、E,权重分别为1、3、5、3、1。对应的直方图如下所示
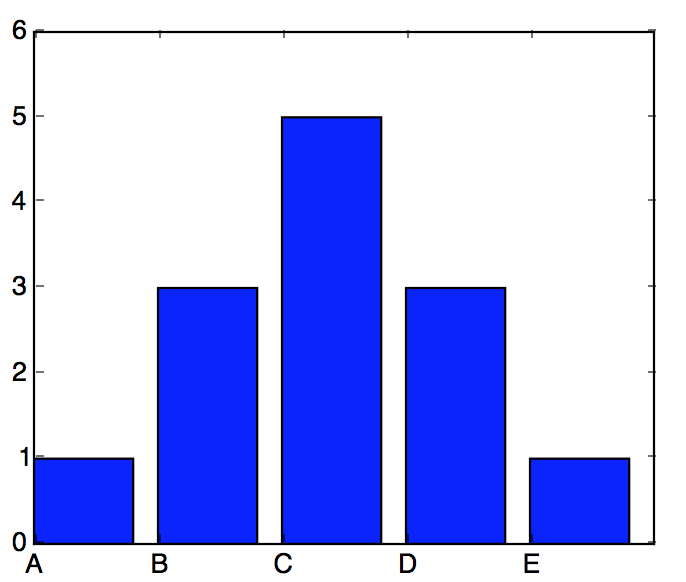
实现思路:按照一个固定的顺序累加每个元素的权重,这样每个元素都会有一个对应的区间
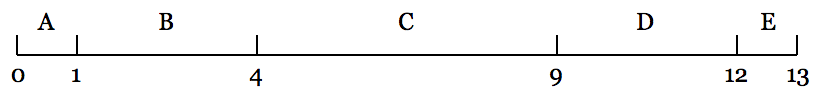
然后随机选择一个(0, sum(权重))之间的随机数(均匀分布),这个数落在哪个区间,则该区间对应的元素即为按权重命中的元素。具体实现时我们借助Java提供的TreeMap和tailMap。首先根据输入数据Pair<元素, 权重>构建一棵由TreeMap实现的权重树。TreeMap底层是由红黑树实现,树中的每个节点都是<权重累加, 元素>类型。然后通过tailMap和随机数从权重树中选择一个元素,该元素即是按权重命中的元素。
Java实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
| import org.apache.commons.math3.util.Pair; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.util.List; import java.util.SortedMap; import java.util.TreeMap; * Created by yzh on 2017/4/19. */ public class WeightRandom<W extends Number, E> { private TreeMap<Double, E> weightMap = new TreeMap<Double, E>(); private static final Logger logger = LoggerFactory.getLogger(WeightRandom.class); public WeightRandom(List<Pair<E, W>> list) { for (Pair<E, W> pair : list) { double lastWeight = this.weightMap.size() == 0 ? 0 : this.weightMap.lastKey().doubleValue(); this.weightMap.put(pair.getValue().doubleValue() + lastWeight, pair.getKey()); } } public E random() { double randomWeight = this.weightMap.lastKey() * Math.random(); SortedMap<Double, E> tailMap = this.weightMap.tailMap(randomWeight, false); return this.weightMap.get(tailMap.firstKey()); } }
|
算法测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
| List<Pair<String, Integer>> list = new ArrayList<Pair<String, Integer>>(); list.add(Pair.create("A",1)); list.add(Pair.create("B",3)); list.add(Pair.create("C",5)); list.add(Pair.create("D",3)); list.add(Pair.create("D",1)); WeightRandom weightRandom = new WeightRandom(list); int a=0,b=0,c=0,d=0; for(int tt = 0; tt < 1000000; tt++){ String s = (String) weightRandom.random(); if (s=="A") a++; else if (s=="B") b++; else if (s=="C") c++; else if (s=="D") d++; } System.out.println("A:"+a+",B:"+b+",C:"+c+",D:"+d);
|
每次从A、B、C、D、E中按照权重1、3、5、3、1随机选择一个元素,运行130万次,结果如下:
| 元素 |
命中次数 |
误差率 |
| A |
100230 |
0.230% |
| B |
299140 |
0.287% |
| C |
500773 |
0.155% |
| D |
299915 |
0.028% |
| E |
99942 |
0.058% |
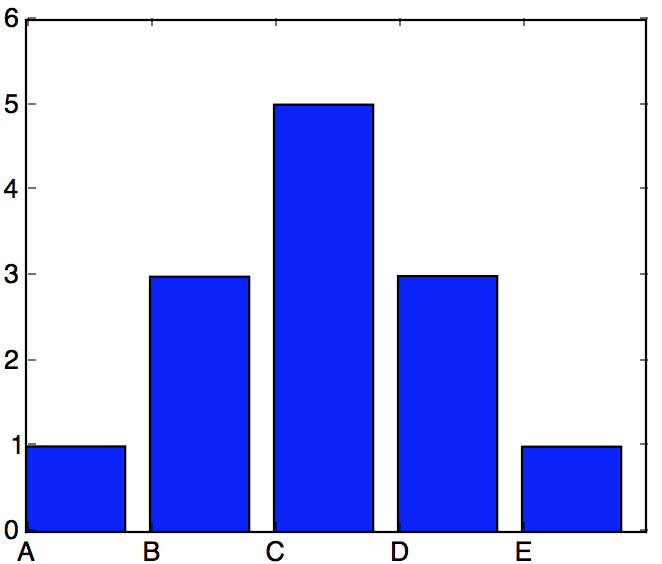
通过上面的表和直方图,可以发现基于权重的随机选择方法,能够很好的达到我们希望的效果。
真实业务场景下的表现
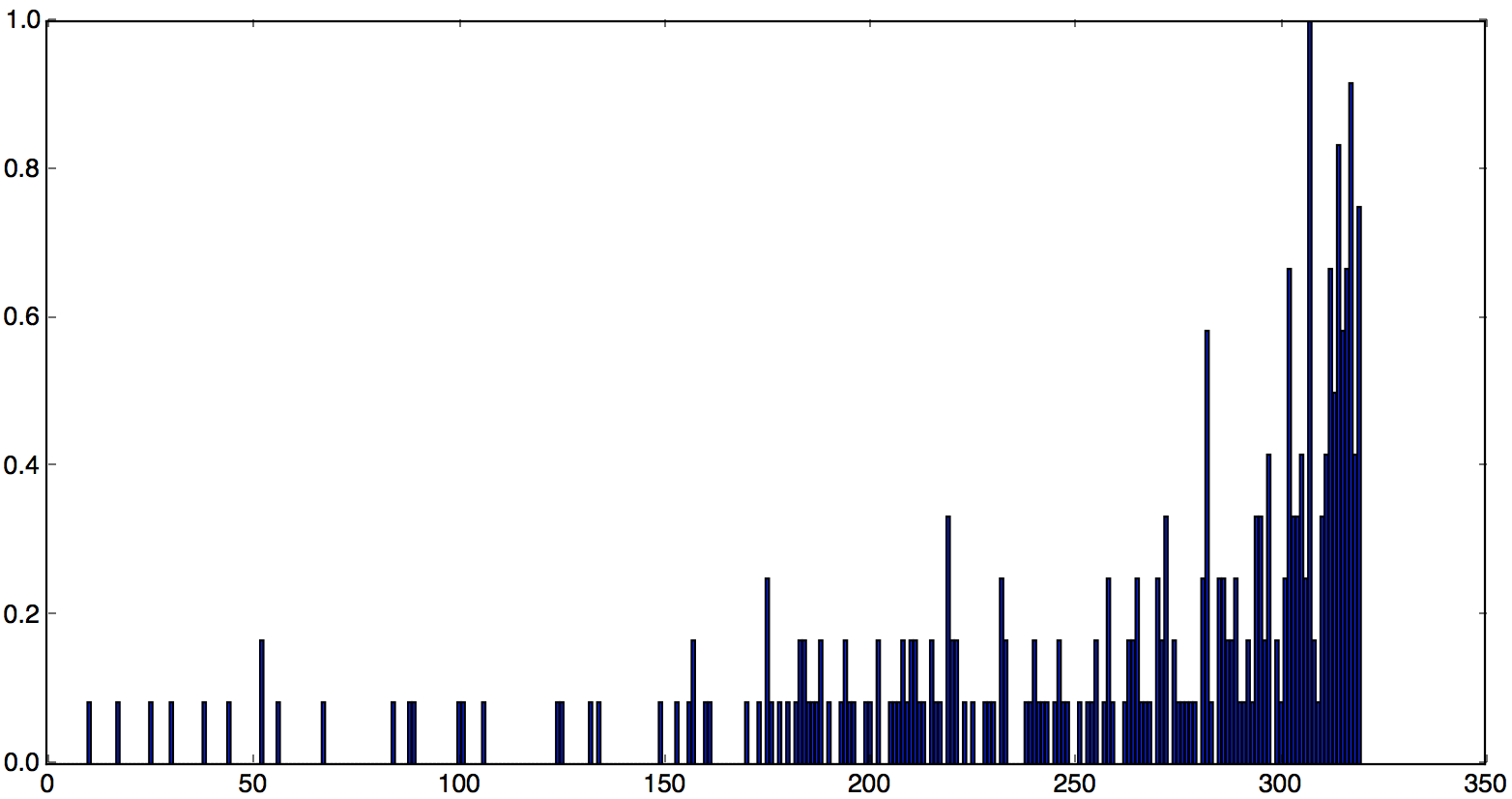
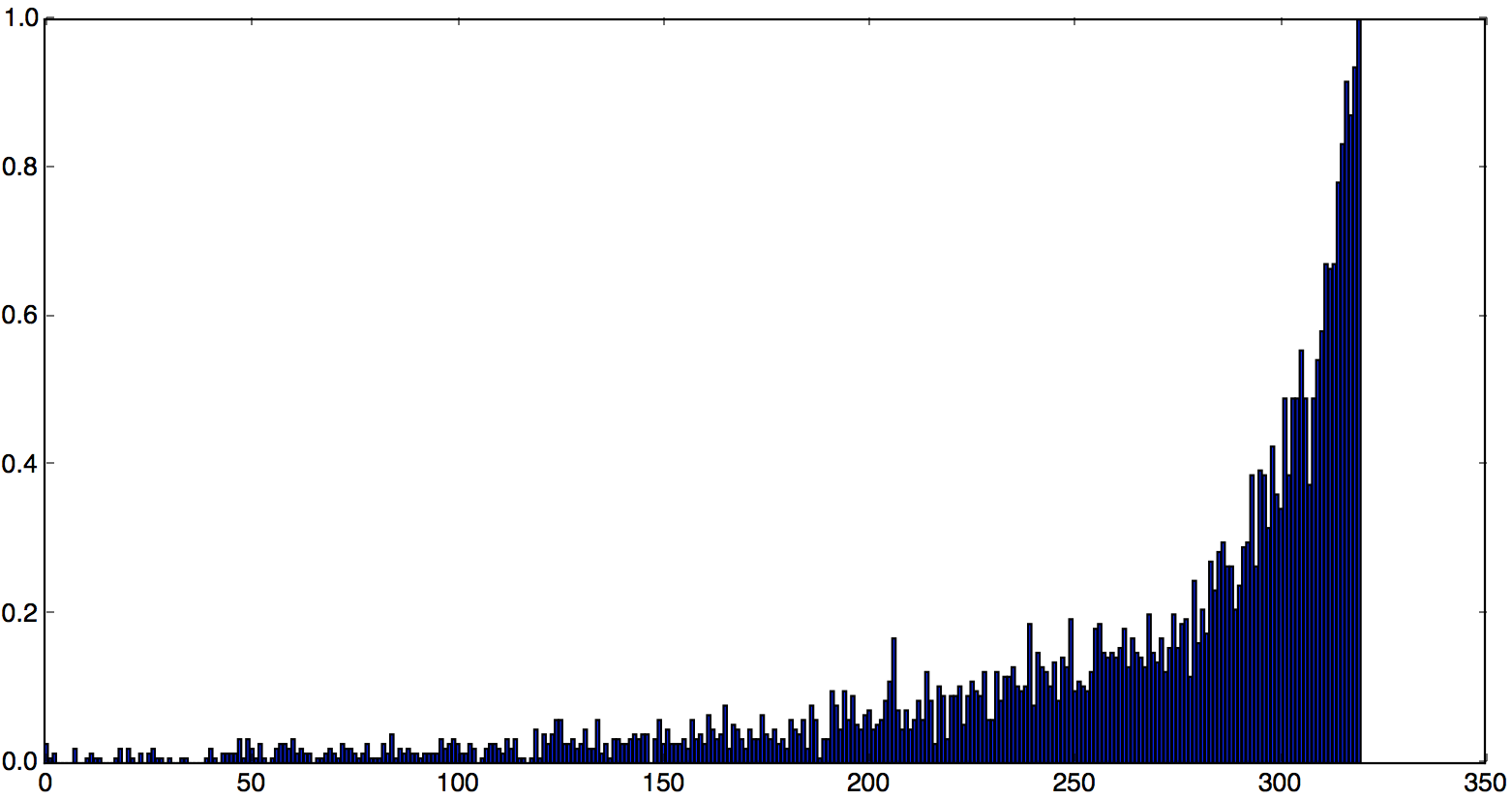
某天某区域的单量为5203单,有320个商家(也就是将5203单分配给320个商家)。将商家的单量作为权重画出的直方图如下,其中x轴是商家,y轴是商家单量。
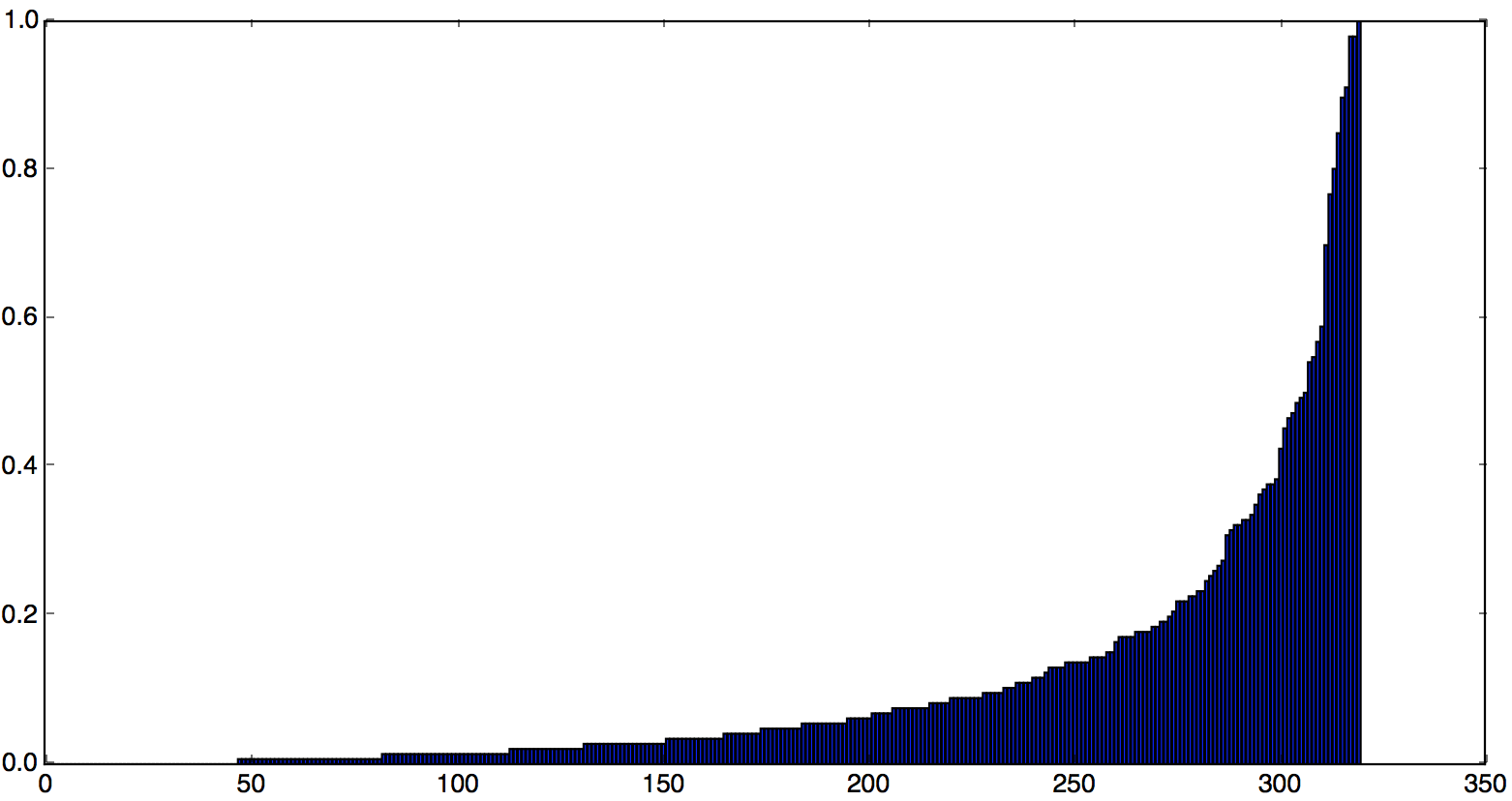
那么当我们为骑手选择初始位置时,也就是将骑手分配给320个商家。下面两个图分别对应骑手数为300和5000的情况。
参考:
- http://www.itdadao.com/articles/c15a108404p0.html